前言
因为毕设是深度学习方面的,所以稍微花了点时间入门深度学习。因为Keras对新手极其友好,所以采用的框架是Keras,比tensorflow封装更好,其后端大多数人也是选择的tensorflow。本文将介绍一些深度学习相关的入门级概念和入门级工程实践。
深度学习入门概念
神经网络
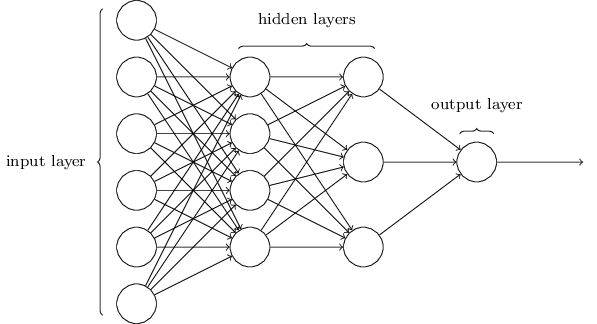
图示为一个简单的前馈神经网络,或者多层感知机(MLP),每一层的输出作为下一层的输入前向传播。神经网络的基础单位是神经元。神经网络常用的训练算法是Backpropagation(反向传播),即根据损失函数的偏导更新权重,达到学习的目的。
激活函数
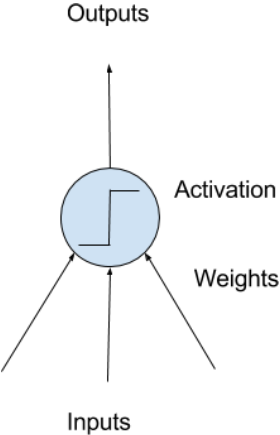
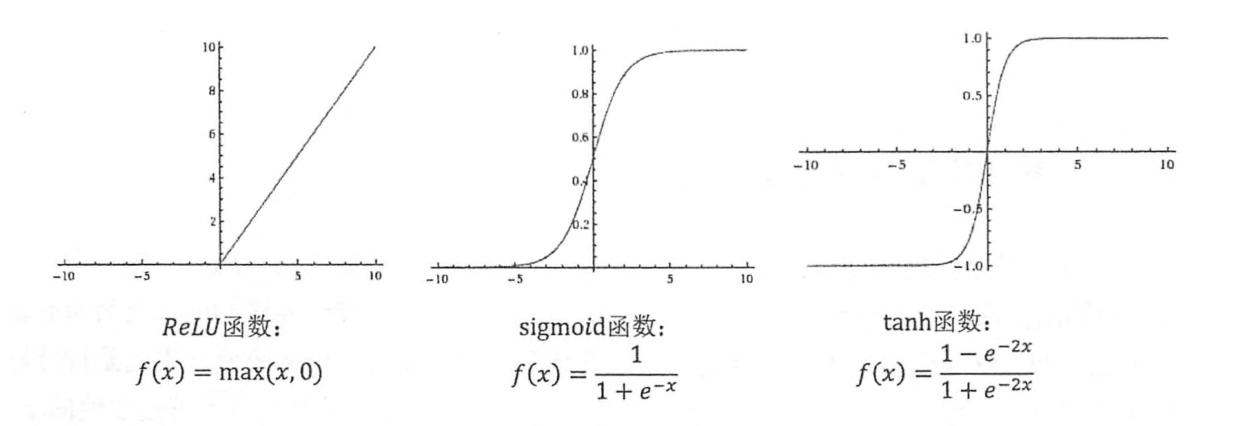
如图示一个神经元的输入和输出,带权重输入经过激活函数后转化成输出。激活函数可以为线性,或者非线性。假如为线性的话,那多层隐层组合的效果和单层效果一样,依然是线性的,所以神经网络一般都用非线性的激活函数。对于进入神经元的来自上一层神经网络的输入向量 x,使用线性整流激活函数relu的神经元会输出max(0,wTx+b)。相对sigmoid函数(s型函数,1/1+exp(-x))来说,relu不容易在两端丢失信息,所以效果更好。看下图就容易理解了:
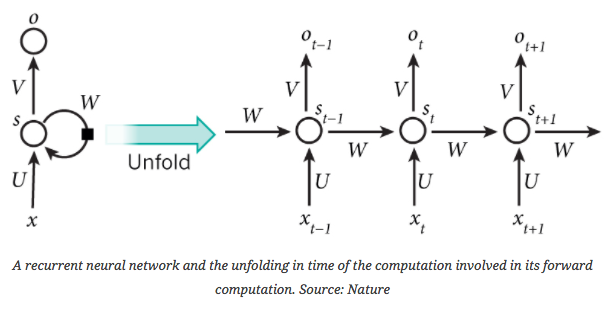
RNN
RNN(循环神经网络)的结构可以简单理解为在通常的多层前反馈神经网络上增加了循环输入,以此来学习序列数据的“顺序”特性。例如当前输入是“很”,根据前一输入是“天空”,我们很容易知道输出大概率是“蓝”,语音识别和语言模型中RNN用处较多。RNN在时间上具有记忆性。其训练算法是Backpropagation through time。
RNN的一个成功应用是LSTM(long short term memory,长短时记忆网络)。
CNN
卷积运算通常用*表示,即:s(t) = (x ∗ w)(t),其中x为输入,w为核函数,s有时称为特征映射。在连续条件下亦可表示为:s(t) = ∫x(a)w(t − a)da。在离散条件下可表示为:s(t) = (x ∗ w)(t) = ∞∑a=−∞ x(a)w(t − a)。
CNN(卷积神经网络)在图像和语音识别方面具备明显优势,一个卷积神经网络主要有以下5个结构:
- 输入层
- 卷积层(Convolutional Layer)
- 池化层(Pooling Layer): 进行池化操作。池化实际是降采样,有多种不同形式的池化函数,“最大池化”是最常见的。通常卷积层之间会周期性插入池化层。以减小参数的空间大小,降低计算量,也控制了过拟合。
- 全连接层(Fully-Connected Layer)
- softmax层
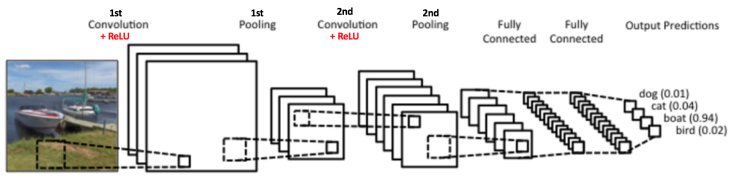
损失函数(Loss)和softmax
损失函数主要评估的是输出的预测结果和真实结果之间的距离,越大则越不准确,所以我们的目标就是要minimize Loss。关于Keras中定义的损失函数可以参考官方文档。在分类问题中使用较多的损失函数是交叉熵(cross-entropy),他刻画了两个概率分布之间的距离。给定两个概率分布p,q,则通过q表示p的交叉熵为: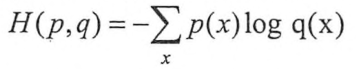
注意交叉熵函数不是关于p,q对称的。因为神经网络的输出并不一定是一个概率分布,所以需要softmax将神经网络的输出转化为概率分布。假设原始输出为y1,y2,…,yn,那经过softmax回归处理后的输出为: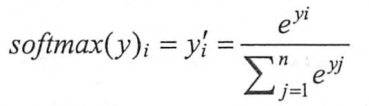
与分类问题不同,回归问题(例如房价预测)一般选用MSE(均方误差,mean squared error,同样也在分类问题中常用)作为损失函数,定义如下: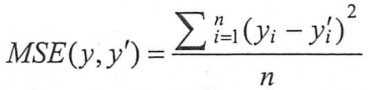
梯度学习和学习率
令𝜽=(w1,w2,....,b1,b2,....),其中w为每个输入的权重,b为每个输入的偏差(bias),bias与数据无关,是模型自带的,决定了神经元产生正负激励的难易程度(即原来输出大于0就是正激励,现在输出要大于b才是正激励),则为了使模型有更好的训练结果,每次更新𝑤 ← 𝑤 − 𝜇 𝜕𝐿/𝜕𝑤,b ← b − 𝜇 𝜕𝐿/𝜕b,其中𝜇是学习率(learning rate),L是损失函数值。这样之后得到的𝜽一般能有效降低L。
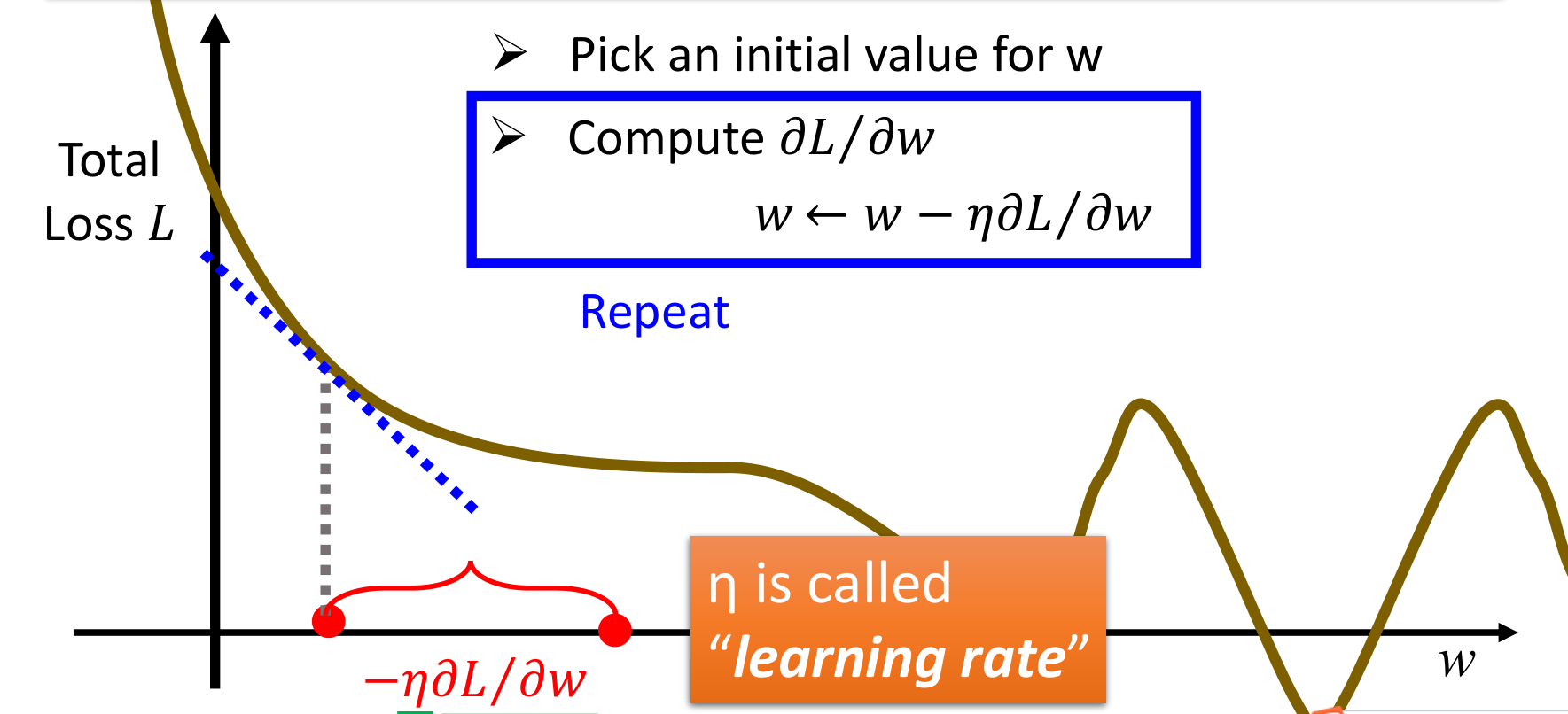
关于学习率如何设置,tensorflow提供了一种比较灵活的学习率设置方法——指数衰减法。tf.train.exponential_decay函数可以实现指数级减小学习率,通过一开始设置一个较大的学习率快速得到一个较优的解,然后随着迭代的进行逐步减少学习率,以使模型达到一个稳定的效果。类似这样:
欠拟合、过拟合、正则化
欠拟合是指模型不能在训练集上获得足够低的误差。而过拟合是指训练误差和测试误差之间的差距太大。过拟合往往是由于模型过分注重拟合训练数据中的噪声,这样导致虽然训练误差下降,但是测试误差却上升。
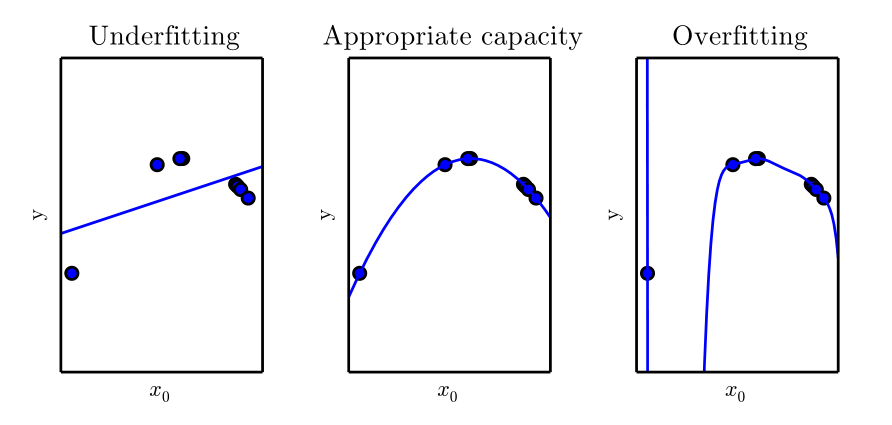
正则化是一种对抗过拟合的方法。正则化的思想是在损失函数中加入刻画模型复杂程度的指标。假如原损失函数为J(𝜽),那么正则化不是直接优化J(𝜽),而是优化J(𝜽)+λR(w)。其中R(w)刻画的是模型的复杂程度,λ是模型复杂损失在总损失中的比例。R(w)有两种,一种是L1正则化,一种是L2正则化,分别对应: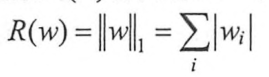
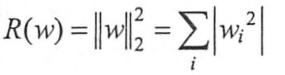
L1会让参数变得稀疏,会有较多权重变为0,达到特征选取的目的。L1不可导,L2可导,所以L2优化起来更简洁。实践中可以将二者结合起来使用: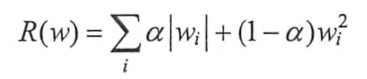
Keras入门实践
Keras可配置backend选项,在/.keras/keras.json(相对home路径)下配置,默认是tensorflow,可选cntk。1
2
3
4
5
6{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
运行 Keras 模型
Keras 的核心概念是模型(model),深度学习模型的构建运行主要包括以下几个步骤:
- 定义模型:创建一个序列(sequence),添加层(layers);
- 编译模型:指定损失函数(loss function),优化器(optimizer),评价指标(metrics);
- 训练模型:载入数据进行训练;
- 模型预测:使用训练好的模型进行预测;
来看一个简单的例子
pima-indians-diabetes.csv是一组糖尿病患者的数据,前8列是所有的numerical属性,最后1列是是否患糖尿病。我们通过Keras建立一个简单的神经网络来建立一个预测糖尿病的模型。
1 | # Create first network with Keras |
运行结果如下,每一轮训练都会输出一个损失率和正确率:1
2
3
4
5
6
7
8
9
10
11
12
13...
Epoch 143/150
768/768 [==============================] - 0s - loss: 0.4614 - acc: 0.7878
Epoch 144/150
768/768 [==============================] - 0s - loss: 0.4508 - acc: 0.7969
Epoch 145/150
768/768 [==============================] - 0s - loss: 0.4580 - acc: 0.7747
Epoch 146/150
768/768 [==============================] - 0s - loss: 0.4627 - acc: 0.7812
Epoch 147/150
768/768 [==============================] - 0s - loss: 0.4531 - acc: 0.7943
Epoch 148/150
768/768 [==============================] - 0s - loss: 0.4656 - acc: 0.7734
其中优化器选用的adam,研究表明其优化性能较好。metric是评估指标,选的accuracy。
再来个10-fold cross validation的例子:
1 | # MLP for Pima Indians Dataset with 10-fold cross validation |
当然这只是最简单的神经网络入门demo,后期还需要学习调参技巧去优化模型,达到更好的训练效果。
参考: