本文为作者原创,转载请注明出处。
前言
上次写了一篇关于JVM的综述,主要讨论了类文件结构和内存管理以及类加载,这次我们来分析下dex文件结构,与java字节码不同,dalvik字节码是小端存储。
依旧是之前Main.java那段程序:1
2
3
4
5
6
7
8
9
10
11public class Main {
private int m;
public int inc() {
return m + 1;
}
public static void main(String[] args) {
System.out.println("hello world");
}
}
我们先通过dx生成对应的dex文件:

再通过adb运行下看看对不对:
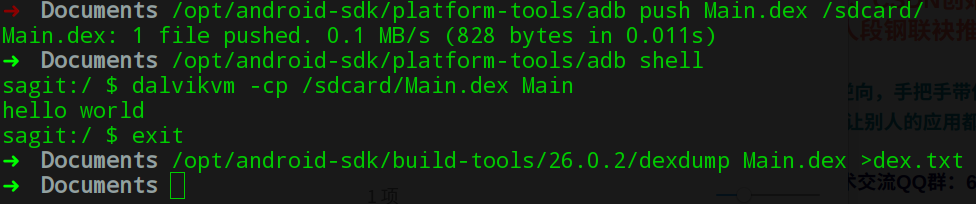
可以看到成功的输出了hello world,另外这里用到了dexdump将解析后的dex结构信息写入到dex.txt以辅助分析。dexdump有以下几个选项,可以帮助我们更好分析dex文件。
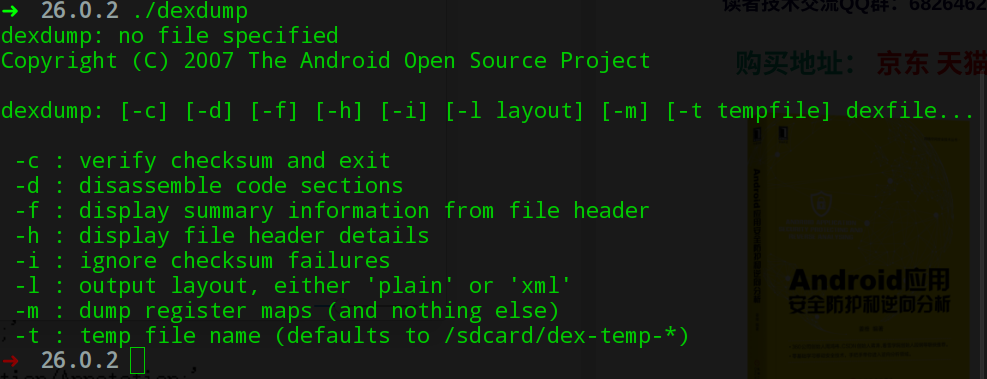
在分析Java字节码的时候我们同样用到了javap工具辅助分析字节码,是不是觉得很相似?废话不多说,我们开始吧。点击这里下载Main.dex可以帮助你更好的跟上我的思路来分析。
大体结构
首先先介绍下dex文件应用到的基础数据结构:byte,ubyte,short,ushort,int,uint,long,ulong这几个都没必要介绍了。加U的都是无符号类型。比较陌生的是这仨:
| 类型 | 含义 |
|---|---|
| sleb128 | 有符号leb128,长度可变,1~5B |
| uleb128 | 无符号leb128,长度可变,1~5B |
| uleb128p1 | 无符号leb128值加1,长度可变,1~5B |
关于leb128这种结构,它由1~5B组成,每个字节最高位如果为1,则表示存在下一字节,为0则表示这是最后一个字节。即最后一个字节最高位是0,其他字节最高位是1。每个字节的剩余 7 位均为有效负荷。
接着来看dex文件大体的结构:
| 名称 | 格式 | 说明 |
|---|---|---|
| header | header_item | 标头 |
| string_ids | string_id_item[] | 字符串标识符列表。这些是此文件使用的所有字符串的标识符,用于内部命名(例如类型描述符)或用作代码引用的常量对象。此列表必须使用 UTF-16 代码点值按字符串内容进行排序(不采用语言区域敏感方式),且不得包含任何重复条目。 |
| type_ids | type_id_item[] | 类型标识符列表。这些是此文件引用的所有类型(类、数组或原始类型)的标识符(无论文件中是否已定义)。此列表必须按 string_id 索引进行排序,且不得包含任何重复条目。 |
| proto_ids | proto_id_item[] | 方法原型标识符列表。这些是此文件引用的所有原型的标识符。此列表必须按返回类型(按 type_id索引排序)主要顺序进行排序,然后按参数列表(按 type_id索引排序的各个参数,采用字典排序方法)进行排序。该列表不得包含任何重复条目。 |
| field_ids | field_id_item[] | 字段标识符列表。这些是此文件引用的所有字段的标识符(无论文件中是否已定义)。此列表必须进行排序,其中定义类型(按 type_id 索引排序)是主要顺序,字段名称(按 string_id 索引排序)是中间顺序,而类型(按 type_id 索引排序)是次要顺序。该列表不得包含任何重复条目。 |
| method_ids | method_id_item[] | 方法标识符列表。这些是此文件引用的所有方法的标识符(无论文件中是否已定义)。此列表必须进行排序,其中定义类型(按 type_id 索引排序)是主要顺序,方法名称(按 string_id 索引排序)是中间顺序,而方法原型(按 proto_id 索引排序)是次要顺序。该列表不得包含任何重复条目。 |
| class_defs | class_def_item[] | 类定义列表。这些类必须进行排序,以便所指定类的超类和已实现的接口比引用类更早出现在该列表中。此外,对于在该列表中多次出现的同名类,其定义是无效的。 |
| call_site_ids | call_site_id_item[] | 调用站点标识符列表。这些是此文件引用的所有调用站点的标识符(无论文件中是否已定义)。此列表必须按 call_site_off 的升序进行排序。 |
| method_handles | method_handle_item[] | 方法句柄列表。此文件引用的所有方法句柄的列表(无论文件中是否已定义)。此列表未进行排序,而且可能包含将在逻辑上对应于不同方法句柄实例的重复项。 |
| data | ubyte[] | 数据区,包含上面所列表格的所有支持数据。不同的项有不同的对齐要求;如有必要,则在每个项之前插入填充字节,以实现所需的对齐效果。 |
| link_data | ubyte[] | 静态链接文件中使用的数据。本文档尚未指定本区段中数据的格式。此区段在未链接文件中为空,而运行时实现可能会在适当的情况下使用这些数据。 |
头部
头部长度固定为0x70,其结构如下:
| 字段名称 | 偏移值 | 长度/byte | 描述 |
|---|---|---|---|
| magic | 0x0 | 8 | 魔数 |
| checksum | 0x8 | 4 | 校验和 |
| signature | 0xc | 20 | SHA-1 签名 |
| file_size | 0x20 | 4 | dex文件总长度 |
| header_size | 0x24 | 4 | 文件长度 |
| endian_tag | 0x28 | 4 | 标志字节顺序的常量 |
| link_size | 0x2c | 4 | 链接段的大小,为0表示静态链接 |
| link_off | 0x30 | 4 | 链接段的开始位置 |
| map_off | 0x34 | 4 | map数据基址 |
| string_ids_size | 0x38 | 4 | 字符串列表中字符串个数 |
| string_ids_off | 0x3c | 4 | 字符串列表基址 |
| type_ids_size | 0x40 | 4 | 类列表里类型个数 |
| type_ids_off | 0x44 | 4 | 类列表基址 |
| proto_ids_size | 0x48 | 4 | 原型列表中原型个数 |
| proto_ids_off | 0x4c | 4 | 原型列表基址 |
| field_ids_size | 0x50 | 4 | 字段列表里字段个数 |
| field_ids_off | 0x54 | 4 | 字段列表基址 |
| method_ids_size | 0x58 | 4 | 方法列表里方法个数 |
| method_ids_off | 0x5c | 4 | 方法列表基址 |
| class_defs_size | 0x60 | 4 | 类定义列表中类个数 |
| class_defs_off | 0x64 | 4 | 类定义列表基址 |
| data_size | 0x68 | 4 | 数据段的大小,必须以4字节对齐 |
| data_off | 0x6c | 4 | 数据段基址 |
从dalvik/libdex/DexFile.h中也能看到其定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/*
* Direct-mapped "header_item" struct.
*/
struct DexHeader {
u1 magic[8]; /* includes version number */
u4 checksum; /* adler32 checksum */
u1 signature[kSHA1DigestLen]; /* SHA-1 hash */
u4 fileSize; /* length of entire file */
u4 headerSize; /* offset to start of next section */
u4 endianTag;
u4 linkSize;
u4 linkOff;
u4 mapOff;
u4 stringIdsSize;
u4 stringIdsOff;
u4 typeIdsSize;
u4 typeIdsOff;
u4 protoIdsSize;
u4 protoIdsOff;
u4 fieldIdsSize;
u4 fieldIdsOff;
u4 methodIdsSize;
u4 methodIdsOff;
u4 classDefsSize;
u4 classDefsOff;
u4 dataSize;
u4 dataOff;
};
下面对Main.dex分析其头部:
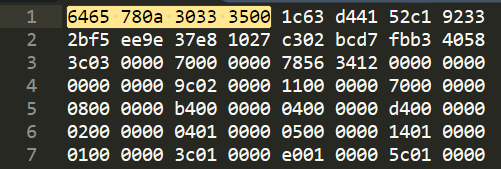
魔数通过查ASCII表可得为dex\n035\0。关于魔数可取的值在dalvik/libdex/DexFile.h中定义如下:
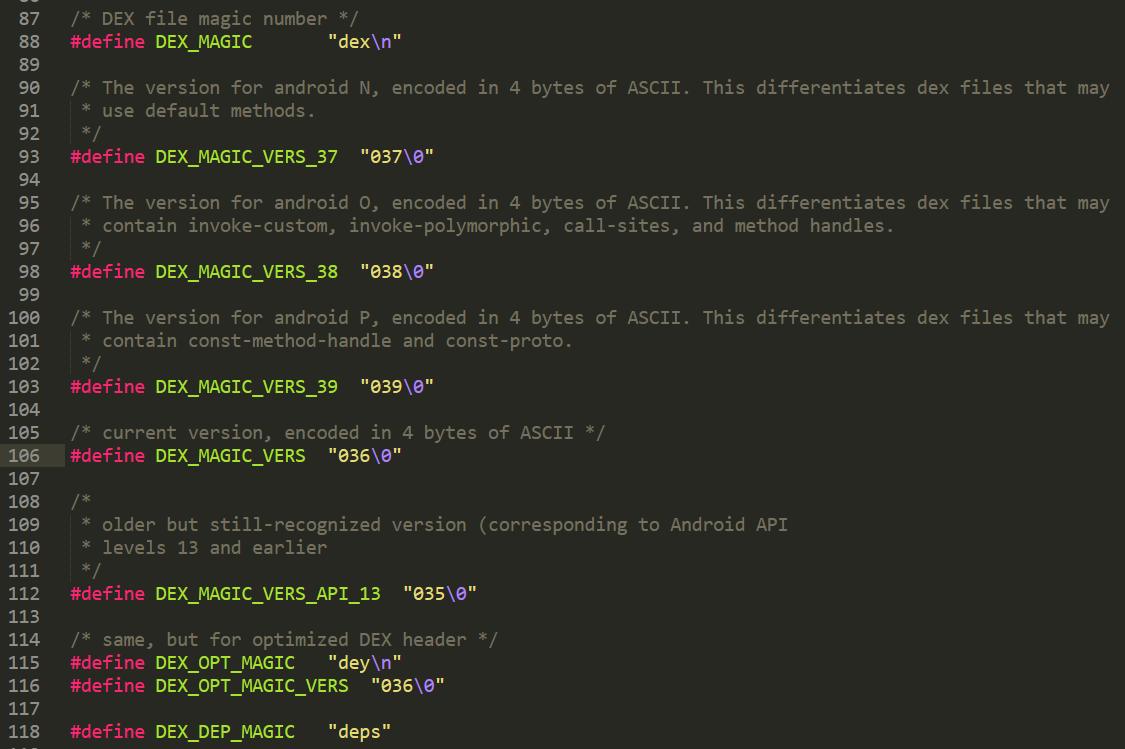
注意:dalvik/libdex/DexFile.h中定义了很多dex文件的结构体,必要时可作为参考。
接下来4个字节是文件校验码 ,使用alder32 算法校验文件除去 maigc ,checksum 外余下的所有文件区域 ,用于检查文件错误 。再接下去是signature , 使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,用于唯一识别本文件 。
接着看file_size是3c03 0000,即0x033c,也就是828个字节。header_size为7000 0000,也就是0x70,112字节。endian_tag为0x12345678,表示小端法。link_size和link_off都是0000 0000,map_off为0x029c,我们找到这个位置的4字节看看。 可见是
可见是0x000d,即13。首先先来看看map数据的格式,即map_list这个数据结构包含:
| 名称 | 格式 | 说明 |
|---|---|---|
| size | uint | 列表的大小 |
| list | map_item[size] | 列表的元素 |
其中map_item这个结构如下:
| 名称 | 格式 | 说明 |
|---|---|---|
| type | ushort | 项的类型;见官方文档 |
| unused | ushort | (未使用,只用来对齐字节) |
| size | uint | 在指定偏移量处找到的项数量 |
| offset | uint | 从文件开头到相关项的偏移量 |
可见map_list的size为13,总共占字节数为12*13+4=160。头部剩下的条目可按此法依次分析,如下表:
| 名称 | 值 | 含义 |
|---|---|---|
| string_ids_size | 0x11 | 字符串列表中字符串个数 |
| string_ids_off | 0x70 | 字符串列表基址 |
| type_ids_size | 0x08 | 类列表里类型个数 |
| type_ids_off | 0xb4 | 类列表基址 |
| proto_ids_size | 0x04 | 原型列表中原型个数 |
| proto_ids_off | 0xd4 | 原型列表基址 |
| field_ids_size | 0x02 | 字段列表里字段个数 |
| field_ids_off | 0x0104 | 字段列表基址 |
| method_ids_size | 0x05 | 方法列表里方法个数 |
| method_ids_off | 0x0114 | 方法列表基址 |
| class_defs_size | 0x01 | 类定义列表中类个数 |
| class_defs_off | 0x013c | 类定义列表基址 |
| data_size | 0x01e0 | 数据段的大小,必须以4字节对齐 |
| data_off | 0x015c | 数据段基址 |
string_ids
因为string_ids偏移地址为0x70,大小为17,所以可知其占的字节如下:

先来看第一个string_id_item所占的字节:be01 0000。在DexFile.h里也能看到string_id_item的定义:1
2
3
4
5
6/*
* Direct-mapped "string_id_item".
*/
struct DexStringId {
u4 stringDataOff; /* file offset to string_data_item */
};
可知第一个string_data_item所在的偏移地址为0x01be,如下(到第一个为0的字节为止):

关于string_data_item的格式在官方文档中定义如下:
| 名称 | 格式 | 说明 |
|---|---|---|
| utf16_size | uleb128 | 此字符串的大小;以UTF-16代码单元(在许多系统中为“字符串长度”)为单位。也就是说,这是该字符串的解码长度(编码长度隐含在 0 字节的位置)。 |
| data | ubyte[] | 一系列 MUTF-8 代码单元(又称八位字节),后跟一个值为 0 的字节。 |
所以我们看到第一个字节为0x06,即string_data长度为6,接下来的3c 696e 6974 3e,查ASCII表可知为<init>。第二个string类似分析,找到c601 0000即0x01c6处的字节为0149,即长度为1,找到0x49对应的ASCII码知是I。剩下的15个string类似分析即可,所得17个string列表如下:
| 索引 | 值 |
|---|---|
| 0 | <init> |
| 1 | I |
| 2 | LMain; |
| 3 | Ljava/io/PrintStream |
| 4 | Ljava/lang/Object |
| 5 | Ljava/lang/String |
| 6 | Ljava/lang/System |
| 7 | Main.java |
| 8 | V |
| 9 | VL |
| 10 | [Ljava/lang/String; |
| 11 | hello world |
| 12 | inc |
| 13 | m |
| 14 | main |
| 15 | out |
| 16 | println |
type_ids
关于type_id_item结构如下:1
2
3
4
5
6/*
* Direct-mapped "type_id_item".
*/
struct DexTypeId {
u4 descriptorIdx; /* index into stringIds list for type descriptor */
};
又根据之前的分析知道有8个type_id_item,基址为0xb4,如下:

descriptorIdx的值为之前算过的string列表的索引,可见8个type分别是string中索引1-6,8,10的项。
proto_ids
之前算到有4个方法原型,偏移为0xd4,找到字节如下:
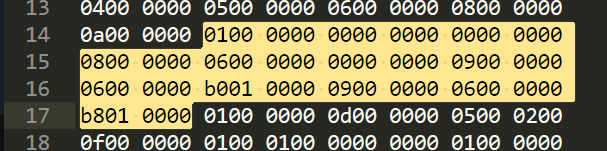
proto_id_item格式如下:
| 名称 | 格式 | 说明 |
|---|---|---|
| shorty_idx | uint | 此原型的简短式描述符字符串的string_ids列表中的索引。 |
| return_type_idx | uint | 此原型的返回类型的type_ids列表中的索引。 |
| parameters_off | uint | 从文件开头到此原型的参数类型列表的偏移量;如果此原型没有参数,则该值为0。该偏移量(如果为非零值)应该位于 data 区段中,且其中的数据应采用下文中“”type_list””指定的格式。此外,不得对列表中的类型void进行任何引用。 |
分析得四个方法原型为:
| 索引 | shorty | return_type | parameters |
|---|---|---|---|
| 0 | I | I | 无 |
| 1 | V | V | 无 |
| 2 | VL | V | 参数在0x01b0处的是0100 0000 0400,即第4个type:Ljava/lang/String |
| 3 | VL | V | [Ljava/lang/String |
后面引用到这个原型列表的时候暂且把列表记做protos。
field_ids
之前分析到有2个field,偏移为0x0104,field_id_item格式如下:
| 名称 | 格式 | 说明 |
|---|---|---|
| class_idx | ushort | 此字段所属的类的type_ids列表中的索引。此项必须是“类”类型,而不能是“数组”或“基元”类型。 |
| type_idx | ushort | 此字段的类型的 type_ids 列表中的索引。 |
| name_idx | uint | 此字段的名称的 string_ids 列表中的索引。该字符串必须符合上文定义的 MemberName 的语法。 |
找到这俩field占的字节如下:0100 0000 0d00 0000,0500 0200 0f00 0000。
即:
| 索引 | class | type | name |
|---|---|---|---|
| 0 | LMain | I | m |
| 1 | Ljava/lang/System | Ljava/io/PrintStream | out |
method_ids
由之前分析知5个method_id_item,偏移为0x0114,其格式如下:
| 名称 | 格式 | 说明 |
|---|---|---|
| class_idx | ushort | 此方法的定义符的type_ids列表中的索引。此项必须是“类”或“数组”类型,而不能是“基元”类型。 |
| proto_idx | ushort | 此方法的原型的 proto_ids 列表中的索引。 |
| name_idx | uint | 此方法名称的 string_ids 列表中的索引。该字符串必须符合上文定义的 MemberName 的语法。 |
找到这些字节码:

即可分析出这五个method:
| 索引 | class | proto | name |
|---|---|---|---|
| 0 | I | protos[1] | <init> |
| 1 | I | protos[0] | inc |
| 2 | I | protos[3] | main |
| 3 | LMain | protos[2] | println |
| 4 | Ljava/io/PrintStream | protos[1] | <init> |
class_defs
// todo 未完待续。。。
参考: