前言
虽然客户端开发接触Java并发没有server那么多,但是基本的同步类以及实现原理还是要有所了解。不然遇到最基础的ConcurrentModificationException都可能不知道怎么处理。这些是最近总结的一些同步知识。
synchronized关键字
我们都知道synchronized关键字对同一个线程具备可重入性,可以修饰block和method,并且都可以作用在类和对象上,但是修饰block和method的时候具体区别在哪儿呢?以下面一段代码为例我们来看下其字节码就知道了。
1 | import java.util.List; |
通过命令行:javac Test.java然后javap -verbose Test可以看到其对应的字节码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93// 省略了很多不重要的信息,加了一点点注释
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=6, args_size=1
// new ArrayList并将引用push到操作数栈
0: new #2 // class java/util/ArrayList
3: dup // 将list引用复制一份push到操作数栈
// 调用实例构造函数,pop list
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1 // 将list存入局部变量表index =1 位置,同时pop
8: aload_1 // 将list取出,push到操作数栈
9: dup // 将list引用复制一份push到操作数栈
10: astore_2 // 将list副本存入局部变量表index =2 位置,同时pop
11: monitorenter
12: iconst_0
13: istore_3
14: iload_3
15: iconst_5
16: if_icmpge 36
19: aload_1
20: iload_3
21: invokestatic #4 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
24: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
29: pop
30: iinc 3, 1
33: goto 14
36: aload_2
37: monitorexit
38: goto 48
41: astore 4
43: aload_2
44: monitorexit
45: aload 4
47: athrow
48: ldc #6 // class Test
50: dup
51: astore_2
52: monitorenter
53: iconst_0
54: istore_3
55: iload_3
56: iconst_5
57: if_icmpge 77
60: aload_1
61: iload_3
62: invokestatic #4 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
65: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
70: pop
71: iinc 3, 1
74: goto 55
77: aload_2
78: monitorexit
79: goto 89
82: astore 5
84: aload_2
85: monitorexit
86: aload 5
88: athrow
89: return
Exception table:
from to target type
12 38 41 any
41 45 41 any
53 79 82 any
82 86 82 any
LineNumberTable:
line 6: 0
line 7: 8
line 8: 12
line 9: 19
line 8: 30
line 11: 36
line 12: 48
line 13: 53
line 14: 60
line 13: 71
line 16: 77
line 17: 89
public static synchronized void test();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=0, args_size=0
0: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #8 // String this is a synchronized method
5: invokevirtual #9 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 20: 0
line 21: 8
}
可以看出 synchronized 修饰代码块的时候会在执行到代码块的前将操作数栈的引用指向锁对象,对于对象锁就是该对象,对于类锁就是这个类名的常量(类锁和对象锁之间不会发生竞争),然后插入一个monitorenter指令;当执行完block的时候会多出2个monitorexit指令,一个是正常执行的路径,另一个是block发生异常的路径,保证无论是否有异常都会执行monitorexit。monitorenter会尝试获得锁,将锁计数加1,monitorexit将释放锁,锁计数减1,锁计数为0则释放锁。
另一方面,synchronized修饰方法时只是给方法的flags加了个ACC_SYNCHRONIZED标志位,由JVM根据这个标志位进行加锁。
atomic
Java.util.concurrent.atomic包提供了一些原子类,使用这些原子类操作数据可以保证原子性。以AtomicInteger为例,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
/**
* Creates a new AtomicInteger with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
/**
* Creates a new AtomicInteger with initial value {@code 0}.
*/
public AtomicInteger() {
}
.......
/**
* Atomically sets to the given value and returns the old value.
*
* @param newValue the new value
* @return the previous value
*/
public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
/**
* Atomically increments by one the current value.
*
* @return the previous value
*/
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
/**
* Atomically decrements by one the current value.
*
* @return the previous value
*/
public final int getAndDecrement() {
return unsafe.getAndAddInt(this, valueOffset, -1);
}
/**
* Atomically adds the given value to the current value.
*
* @param delta the value to add
* @return the previous value
*/
public final int getAndAdd(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta);
}
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
/**
* Atomically decrements by one the current value.
*
* @return the updated value
*/
public final int decrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, -1) - 1;
}
/**
* Atomically adds the given value to the current value.
*
* @param delta the value to add
* @return the updated value
*/
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
其内部是通过Unsafe类提供的一些native方法实现同步操作。类似的还有AtomicReference
Unsafe类提供类获取Unsafe单例的方法,但是因为限制了调用getUnsafe的类只能是使用BootstrapClassloader加载的类(BootstrapClassloader用于加载JDK核心类库),所以我们无法直接getUnsafe调用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public final class Unsafe {
// 单例对象
private static final Unsafe theUnsafe;
private Unsafe() {
}
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
// 仅在引导类加载器`BootstrapClassLoader`加载时才合法
if(!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
}
但是我们可以通过反射获取:1
2
3
4
5
6
7
8
9
10private static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
log.error(e.getMessage(), e);
return null;
}
}
ReentrantLock
ReentrantLock和synchronized一样具备可重入性,但是区别在于:
- ReentrantLock支持构造函数传入boolean值选择公平锁(FIFO)还是非公平锁(锁被释放的时候如果正好有线程请求锁则直接允许,否则才唤醒等待队头的线程),默认false非公平锁。因为线程上下文切换开销不小,所以非公平锁性能要优于公平锁。
- ReentrantLock是可中断的,使用lockInterruptibly可以对中断做出响应,在获得锁之前停止休眠。还有一个tryLock作用类似,如果超时或者被中断可以在没获得锁的情况下停止休眠
CountDownLatch
CountDownLatch是能让一个或者多个线程在一系列操作完成之前一直等待的工具,初始化会设置一个计数,为1时相当于一个简单的开关,为N时只有当N个线程都执行完并调用countDown()后才会接着执行当前线程await后面的代码(每次调用countDown()计数器会减1)。计数器不能重置,如果需要重置可以考虑用CyclicBarrier(没用过)。CountDownLatch是通过AQS实现的。AQS内部通过一个dequeue和flag来维护等待队列。
Semaphore
Semaphore是计数的信号量,初始化设置一个值x,可以理解为维护大小为x的permits集合。acquire() 方法可以使用一个permit,如果无可用permit则会block。release() 将释放一个正在使用的permit。Semaphore可以保证任何时候任何情况下都只有最多x个permit在使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* Creates a {@code Semaphore} with the given number of
* permits and nonfair fairness setting.
*
* @param permits the initial number of permits available.
* This value may be negative, in which case releases
* must occur before any acquires will be granted.
*/
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
/**
* Creates a {@code Semaphore} with the given number of
* permits and the given fairness setting.
*
* @param permits the initial number of permits available.
* This value may be negative, in which case releases
* must occur before any acquires will be granted.
* @param fair {@code true} if this semaphore will guarantee
* first-in first-out granting of permits under contention,
* else {@code false}
*/
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
Semaphore也是基于AQS的共享锁来实现的。
Condition
Condition本质上和Lock绑定在一起。我们通常使用Lock的newCondition()方法创建Condition实例(实际上就是new了一个ConditionObject,ConditionObject维护了一个等待队列),在获取到锁后调用await()可以suspend当前线程,让出锁,等其他线程用完锁后调用signal()再唤醒当前线程。ArrayBlockingQueue就是通过condition来实现的一个生产者消费者模式的数据结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* Serialization ID. This class relies on default serialization
* even for the items array, which is default-serialized, even if
* it is empty. Otherwise it could not be declared final, which is
* necessary here.
*/
private static final long serialVersionUID = -817911632652898426L;
/** The queued items */
final Object[] items;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
.......
/**
* Inserts element at current put position, advances, and signals.
* Call only when holding lock.
*/
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
/**
* Extracts element at current take position, advances, and signals.
* Call only when holding lock.
*/
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
.......
/**
* Creates an {@code ArrayBlockingQueue} with the given (fixed)
* capacity and default access policy.
*
* @param capacity the capacity of this queue
* @throws IllegalArgumentException if {@code capacity < 1}
*/
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
/**
* Creates an {@code ArrayBlockingQueue} with the given (fixed)
* capacity and the specified access policy.
*
* @param capacity the capacity of this queue
* @param fair if {@code true} then queue accesses for threads blocked
* on insertion or removal, are processed in FIFO order;
* if {@code false} the access order is unspecified.
* @throws IllegalArgumentException if {@code capacity < 1}
*/
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
.......
/**
* Inserts the specified element at the tail of this queue, waiting
* for space to become available if the queue is full.
*
* @throws InterruptedException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
.......
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
再谈ConcurrentModificationException和Collection线程安全
ConcurrentModificationException
我们都知道在forEach循环的时候不能直接对集合元素进行增删,否则会抛出ConcurrentModificationException。但是原因是为何呢?其实对于Iterable类型的forEach语法糖,本质上还是用的iterator,以下面一段简单的代码为例:1
2
3
4
5
6
7List<Integer> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
list.add(i);
}
for (int i : list) {
System.out.println(i);
}
我们将这段代码通过javac compile成class后再利用其他decompiler给decompile回Java就可以看到等同于:1
2
3
4
5
6
7
8java.util.ArrayList localArrayList = new java.util.ArrayList();
for (int i = 0; i < 5; i++) {
localArrayList.add(Integer.valueOf(i));
}
for (Iterator localIterator = localArrayList.iterator(); localIterator.hasNext();) {
int j = ((Integer)localIterator.next()).intValue();
System.out.println(j);
}
这验证了我们说的forEach实际上就是iterator实现的。
这里多说一句:如果对数组进行forEach的话则不是iterator,而是for循环遍历下标。同时,我们推荐对forEach中的变量使用final修饰,例如for (final String s : list)。当foreach变量和集合元素类型不一致时,规则如下:1
2List<? extends Integer> l = ...
for (float i : l) ...
将被翻译成:1
2
3for (Iterator<Integer> #i = l.iterator(); #i.hasNext(); ) {
float #i0 = (Integer)#i.next();
...
我们再回到之前的话题,为什么forEach里不能增删这个arrayList里的元素呢?ArrayList中iterator的next方法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
expectedModCount是iterator中的变量,在iterator创建的时候赋值为modCount。每一次iterator的操作都会同步一次expectedModCount = modCount;但是由于我们直接通过ArrayList去add或者remove,就导致modCount变化了,而没有同步给expectedModCount,在下一次iterator的next方法时候判断二者不等,就抛出异常ConcurrentModificationException。那么如何规避呢?方法很多,例如:
- 最容易想到的自然是将forEach换成iterator了
- 其次把forEach换成for循环也可以规避 // 当然这样会有别的问题,不推荐
- 直接将ArrayList换成CopyOnWriteArrayList也能解决
- 通过将集合中的元素拷贝一份,利用拷贝得到的元素进行forEach而不是原集合进行forEach。
这里详细说下第四种吧,这其实也是CopyOnWriteArrayList的原理。在Android源码中也有类似场景,activity生命周期回调执行的时候都会dispatch给Application里的LifecycleCallbacks,我们来看一下:1
2
3
4
5
6
7
8
9
10
11
12
13
protected void onStart() {
if (DEBUG_LIFECYCLE) Slog.v(TAG, "onStart " + this);
mCalled = true;
mFragments.doLoaderStart();
getApplication().dispatchActivityStarted(this);
if (mAutoFillResetNeeded) {
getAutofillManager().onVisibleForAutofill();
}
}
举例,Activity onStart的时候调了Application的dispatchActivityStarted1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/* package */ void dispatchActivityStarted(Activity activity) {
Object[] callbacks = collectActivityLifecycleCallbacks();
if (callbacks != null) {
for (int i=0; i<callbacks.length; i++) {
((ActivityLifecycleCallbacks)callbacks[i]).onActivityStarted(activity);
}
}
}
private Object[] collectActivityLifecycleCallbacks() {
Object[] callbacks = null;
synchronized (mActivityLifecycleCallbacks) {
if (mActivityLifecycleCallbacks.size() > 0) {
callbacks = mActivityLifecycleCallbacks.toArray();
}
}
return callbacks;
}
可以看到这里是先将集合转成数组(这里对集合进行了加锁,确保多线程下的数组和集合一致),利用数组去iterate,同时如果有对集合元素的增删也将作用在集合上,这样就能确保不会出现ConcurrentModificationException(虽然这里源码并不是用的forEach,所以肯定不会出现ConcurrentModificationException,但是即使换成forEach一样不会出现ConcurrentModificationException)
CopyOnWriteArrayList
我们再来看下CopyOnWriteArrayList里是怎么实现的吧。首先同ArrayList一样,CopyOnWriteArrayList也是靠Object数组array存储元素的,不同的是加了volatile修饰,volatile保证里多线程下的可见性,即线程A对array进行写操作后,其他读array的线程也将立即更新各自的array缓存,保证读到的是最新的array值。
其次CopyOnWriteArrayList的iterator保存了一份array副本,使用副本遍历,所以无需校验modCount,同理也不支持set,remove,add操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60static final class COWIterator<E> implements ListIterator<E> {
/** Snapshot of the array */
private final Object[] snapshot;
/** Index of element to be returned by subsequent call to next. */
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
public boolean hasPrevious() {
return cursor > 0;
}
("unchecked")
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
("unchecked")
public E previous() {
if (! hasPrevious())
throw new NoSuchElementException();
return (E) snapshot[--cursor];
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code remove}
* is not supported by this iterator.
*/
public void remove() {
throw new UnsupportedOperationException();
}
public void set(E e) {
throw new UnsupportedOperationException();
}
public void add(E e) {
throw new UnsupportedOperationException();
}
........
}
既然CopyOnWriteArrayList不支持iterator的add,那我们直接看一下CopyOnWriteArrayList自身的add:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
可知add之前使用了ReentrantLock加锁,以保证多线程下不会出现并发问题。
HashMap
再来看HashMap的同步问题:
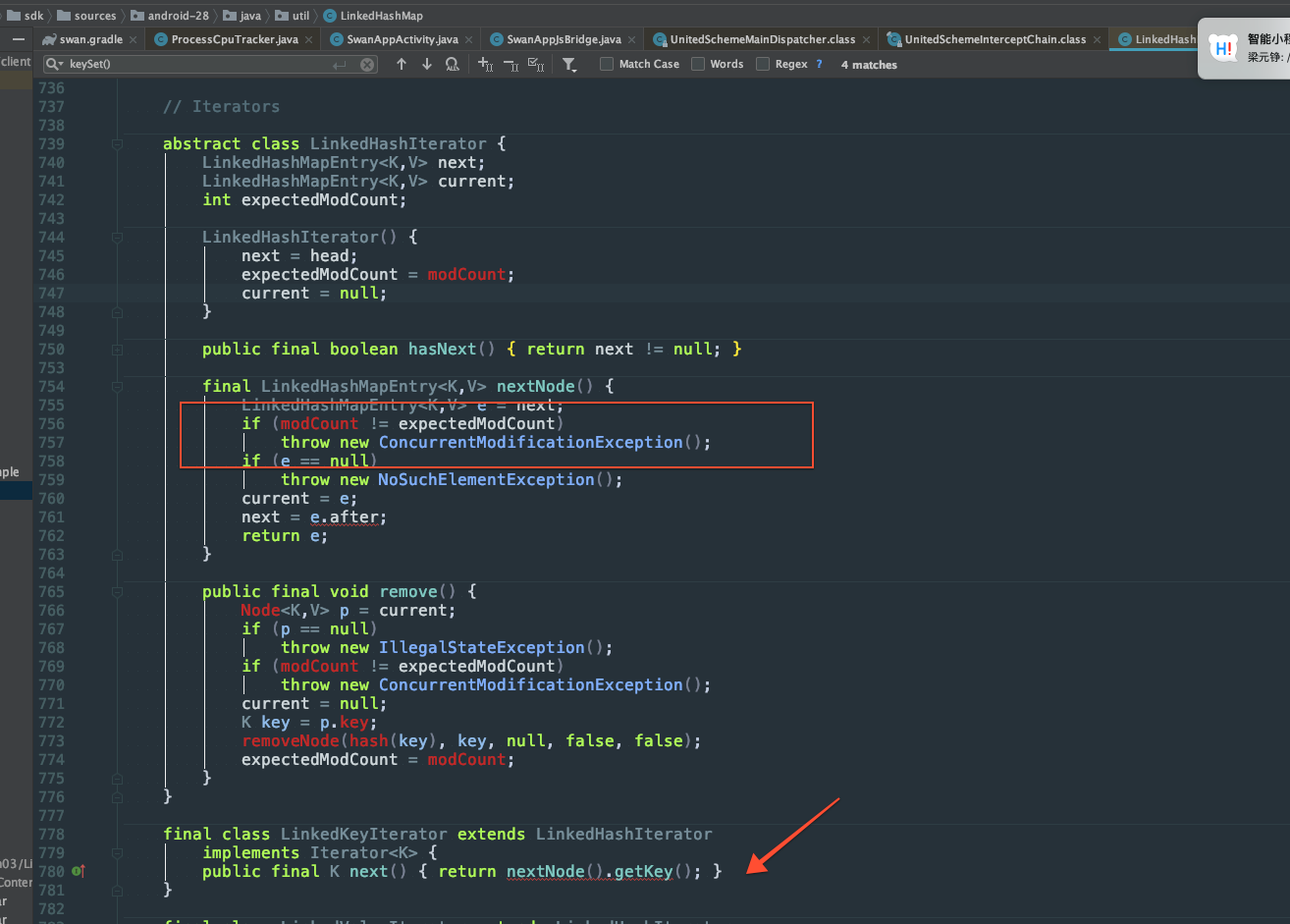
和前面分析的一样,其iterator也是判断ModCount和expectedModCount不想等的时候就抛出ConcurrentModificationException。怎么让HashMap变得线程安全呢?
- 用迭代器进行迭代和增删
- 用迭代器迭代和不用迭代器增删前都需要先请求同一个锁
- 使用ConcurrentHashMap
- 使用Collections.synchronizedMap把HashMap变程同步的map
先看下Collections.synchronizedMap,其实不光map,set,list都可以通过此法转成线程安全的集合。但是此法不推荐,因为其实现原理也是把自己作为锁,所有操作之前先请求锁来保证自身线程安全。但是,其iterator是非线程安全的。也就是说,用迭代器迭代和不用迭代器增删同时发生的时候依然会抛出ConcurrentModificationException。那么如何使用呢?看官网的示例:

ConcurrentHashMap在Java8中是通过CAS和红黑树实现的,其在大小小于等于8的时候使用链表存储。put的时候如果目标key的value是null,就使用CAS操作赋值,不为null就对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过8,则将该链表转换为树,从而提高寻址效率。put不允许传入的key或者value为null。对于get,由于数组使用volatile修饰,不需要担心可见性问题。Hash算法:取hashCode,与右移16位后的结果异或,保证最高位是0以确保正数。1
2
3static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
参考: